Introduction
For over thirty years Relations Database Management Systems (RDBMS) has been the de facto choice for an applications data storage needs. In the recent years RDBMS domination over the storage space has been challenged due to need to store huge amounts of structured, semi structured and unstructured data. The recent explosion in data, both structured and unstructured, has made the need to scale and handle non relational data imperative. International Data Corporation (IDC) estimates that the worlds digital information is doubling every two year a large part of which is semi structured or unstructured data. This has led to the emergence of a large number of open source and commercial RDBMS alternatives.
Scaling Database
So what is scalability? Scalability of a DBMS is its ability to handle a growing workload in an efficient and cost effective manner. There are essentially two ways to scale a database:
- Vertical Scaling - Vertical scaling is also known as scaling up. Vertical scaling refers to adding more resource to a single node i.e. adding in additional CPU, RAM and Disk to enable a single node to handle a growing workload. Vertical scaling has a number of limitations the most obvious one being outgrowing the largest available system. Vertical scaling is also more expensive as your grow. Cost wise scaling vertically is not linear.
- Horizontal Scaling - Horizontal scaling is sometimes referred to as scale out. Horizontal scaling is adding capacity by increasing the number of machines/nodes to a system so that each node can share the processing. Horizontal scaling is a cheaper and more flexible option. This flexibility does come with a cost. Sharing processing and storage amongst an army of nodes is complex.
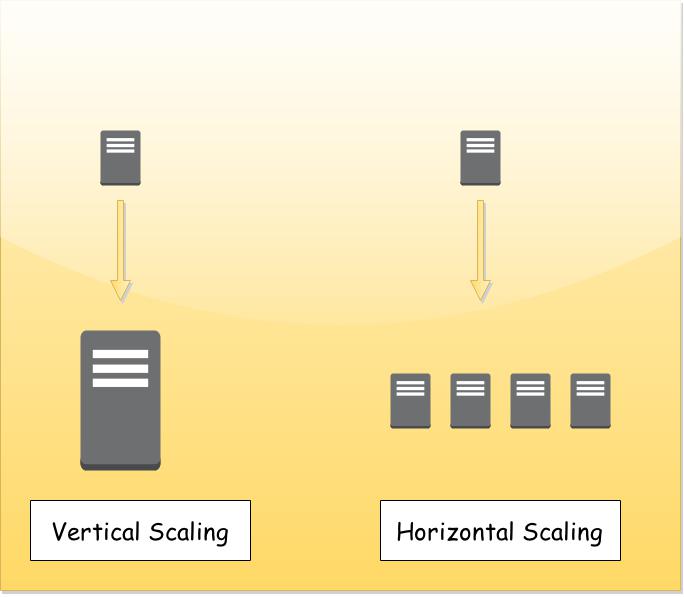
Vertical vs Horizontal Scaling
New and emerging databases prefer to scale horizontally essentially because:
- Capacity can be increased on the fly.
- Cost effective in comparison to vertical scaling
- And in theory it is infinitely scalable since adding nodes increases capacity proportionally.
Hardware Deployment Considerations
In order to understand the evolution in database design is it imperative to understand possible hardware deployment architectures. Essentially there are three different hardware architectures used by database systems.
- Shared Memory i.e. Traditional Deployment Architecture - Shared memory is the standard traditional hardware architecture used by database systems. This architecture is characterised by having a number of cores sharing a block of RAM via a common cache and memory bus. Scaling using this approach (vertical scaling) is essentially buying bigger and better hardware i.e you scale by adding more CPU, RAM to your existing machine. Highly parallel shared memory machines are one of the cash cows of the hardware industry. Traditionally RDBMS database have been designed and worked well on shared memory architecture.
- Shared Disk - A shared disk approach is characterised by a number of independent nodes which have their own RAM and CPU but share a common disk. Shared disk file systems use Storage Area Network (SAN) to provide direct disk access from multiple computers at a block level. The Shared Disk architecture has gained traction with the rise in popularity of a Storage Area Networks (SAN). Popular RDBMS such as Oracle and MS SQL use a shared disk architecture in order to scale horizontally.
- Shared Nothing - A shared nothing architecture is characterized by having a cluster of independent machines communicating over a high speed network. There is no way of accessing memory or disk of another system. It is up to the database implementor to coordinate efficiently among various machines. Each part of a cluster stores a portion of the data and thus data storage is spread across the cluster. The main advantage of this approach is the ability to scale. Shared nothing architectures are scalable linearly because there is no single bottleneck in the architecture and have been proven to scale linearly.
ACID, BASE & THE CAP Theorem
ACID
Jim Gray in the 1970 defined a set properties for all storage engines to strive for. A few years later Andreas Reuter and Theo Härder officially coined the term ACID which described Jim Gray’s set of properties. ACID became a de facto standard for all database to conform to. ACID acronym stands for the following:
- Atomicity - All or nothing i.e. within a transaction (A transaction is a logical unit of work or a group of related changes) either the entire logical unit of related changes are performed or none of them take effect.
- Consistency - Ensures that all data written to a database will always be valid according all rules defined in the database. No database rules or constraints will ever be violated when a transaction is executed.
- Isolation - Must make sure that no transaction has access to data as a result of an unfinished or currently processed transaction. Each transaction is independent and is not affected by other transactions. Of the four ACID properties the isolation property is the most configurable and often the most relaxed. The ANSI/ISO SQL standard defines a number isolation levels which are implemented by most DBMS. These include Serializable, Repeatable reads, Read committed, Read uncommitted. A detailed discussion on isolation level is beyond the scope of this post.
- Durability - Ensures that the results on a transactions are stored permanently once the transaction has been completed.
CAP
The CAP theorem by Eric Brewer states that a distributed database can only guarantee /strongly support two of the following three properties:
- Consistency - A guarantee that every node in a distributed cluster will return the most recent write i.e. every node will return the same data.
- Availability - Every non failing node returns a response in a reasonable amount of time.
- Partition Tolerance - The system will continue to function inspite of network partitions.
BASE
Eventual consistency is a consistency approach that guarantees all changes are eventually replicated across the replica set. Thus eventually all replicas will return the same last updated value. Eventually consistent database are often said to be providing BASE (Basically Available, Soft state, Eventual consistency) semantics. BASE refers to:
- Basically available indicates that the system does guarantee availability, in terms of the CAP theorem i.e. every non failing node returns a response in a reasonable amount of time.
- Soft state indicates that the state of the system may change over time, even without input. This is because of the eventual consistency model.
- Eventual consistency indicates that the system will become consistent over time, given that the system doesn't receive input during that time.
NoSQL Database
NoSQL database refer to a group of databases that do not follow the traditional relational data model. Google and Amazon were one of the first companies required to store large amounts of data. They essentially found that storing data in a relational database did not allow them to store the vast amount of data in a cost effective manner. They pursued alternative approaches successfully and published their findings in seminal papers Bigtable: A Distributed Storage System for Structured Data and Dynamo: Amazon's Highly Available Key-value Store respectively. It is rumoured that Jeff Bezos was livid with the publication of Amazon’s paper as he believed that it gave away too much of Amazon’s secret sauce.
Although there were a number of NoSQL database prior to the publication of these papers the the NoSQL (Not Only SQL) movement gained popularity and a number of new open source and commercial NoSQL were inspired by these papers.
NoSQL database have grown in popularity due to their ability to scale horizontally and handle unstructured and semi structured data efficiently.
Key Features of a NoSQL Database
The main characteristics of a NoSQL database are:
- Based on distributed computing - Unlike traditional RDBMS, NoSQL database have been designed to favour distributed computing and a shared nothing architecture. This is essentially because scaling horizontally is believed to be the only cost effective way of handling large volumes of data. Additionally horizontally scaled databased is a simpler way to handle large workloads.
- Commodity Hardware - Most NoSQL database have been designed to run on cheap commodity hardware (in reality high end commodity hardware) instead to high end servers. This has mainly been done in order to enable scaling in a cost effective manner.
- ACID, BASE and the CAP Theorem - NoSQL database have traded one or more of the ACID (atomicity, consistency, isolation and durability) properties for BASE properties (Basic Availability, Soft-state, Eventual consistency). As all new NoSQL databases use distributed computing and due to the limitations placed by the CAP theorem NoSQL database have chosen BASE (Basic Availability, Soft-state, Eventual consistency) over ACID. While ACID is a pessimistic approach and forces consistency at the end of each transaction, BASE is an optimistic approach where by it accepts that data will be in a state of flux but will eventually sort itself out. Choosing BASE over ACID enables systems to scale horizontally (This might not be entirely true with the advent of NewSQL databases). The definition of the BASE properties follow.
- Provide a flexible schema - In order to store the large growing amount of semi structured and unstructured data developers need a flexible solution that easily accommodates different types of data. Additionally due to the constant change in requirements a schema which is easily evolvable is also required. Thus most new NoSQL database generally provide a flexible schema which can be easily evolved as opposed to the rigid schemas required by RDBMS. This has made working with semi structured and unstructured data a lot easier.
NoSQL Database Categories
NoSQL database can be broadly categorized into four types:
- Key-Value databases - Key value stores provide a simple form of storage that can only store pairs of keys and values. Values stored are essentially blobs and can be retrieved based on keys provided. Some key values stores persist data to disk while others such as Memcached keeps data in memory only. Riak, Redis, Amazon Dynamo DB, FoundationDB, MemcacheDB, and Aerospike are examples of popular key value stores.
- Document Databases - Document Stores are an advanced form of a key value store where the value part store is not a blob but a well known document format. The format of the document are generally XML, JSON, BSON. Since the format of the document is stipulated it enables the database to examine the document. It also enables the database to do operations on the document. Popular Document stores include RavenDB, Apache CouchDB, Couchbase, MarkLogic and MongoDB
- Column Family Databases - Column family based (not to be be confused with column oriented) database are again an evolution of the key value store where the value part contains a collection of columns. Each row in a column family has a key and associates an arbitrary number columns with it. This is useful for accessing related data together. Popular column family based databased include Apache Cassandra, HBASE and Hypertable.
- Graph Databases - A graph database is one which uses a graph structure to store data. Graph database enable you to store entities and establish relationships between these entities.
Apache Cassandra
Apache Cassandra is an open source distributed storage system which was initially developed at Facebook and in 2009 open sourced to the Apache Foundation. Cassandra was conceptualized in one of Facebook's hackathons to solve their storage needs for Facebook's Inbox search problem. The original note by Avinash Lakshman, the person credited for creating Cassandra, outlines his vision for Cassandra. Over the past six years Cassandra has come a long way. DataStax has a very interesting write up comparing the original Cassandra paper with Apache Cassandra latest 2.0 release highlighting how Apache Cassandra has evolved over the years. Today Cassandra is used by a number of companies including NetFlix, Instagram, eBay, Twitter, Reddit and Apple. Recently it was revealed that Apple has one of the largest production of Cassandra deployment, a mind blowing 75,000 nodes storing over 10 PB of data.
Key features provided by Apache Cassandra are:
- Distributed Storage System - Databases in a nutshell are have two main tasks storage and computation. Distributed systems accomplish the two main tasks by using an army of nodes instead of a single node as the problem no longer can be solved by a single node. Cassandra runs on a cluster of nodes using a shared nothing architecture as it is designed to store a huge amounts of data.
- Runs on Commodity Hardware - Like most distributed systems Apache Cassandra has been designed to run on commodity hardware. This enables Cassandra to scale in a cost effective manner.
- Fault Tolerant - When running an application on a cluster of nodes network, hardware and system failures are a reality. Cassandra has been designed from the ground up to work in an acceptable manner in spite of faults in the system.
- Linearly Scalable - Cassandra is linearly scalable i.e. doubling the number of nodes in your cluster doubles the performace. This linear scalability has enabled Cassandra to handle terabytes of data and thousands of concurrent operations per second. Netflix has done a benchmark where it is shown that Cassandra scales linearly and is able to perform one million writes per second.
- AID Support - Cassandra delivers atomicity, isolation and durability but this is not within the bounds of a transaction. Apache Cassandra does not support the traditional RDBMS concept of a transaction. It does support AID within the bounds of a single operation.
- Elastically Scalable - Apache Cassandra is able to elastically scale i.e. it is able to cope with growing/shrinking loads dynamically. It is able to expand and shrink resources according to the workload. This is especially important when using cloud resources as cloud resources follow a pay-per-use model.
- Multi Data Center - Cassandra is architected so that it can be easily deployed across multiple data centres. Clusters can be configured for optimal geographical distribution so cater for redundancy, fail over and disaster recovery.
In my next post, Apache Cassandra Architecture, I explore Cassandra's architecture.
Nice article